Performance Considerations for Enterprise VDI
[This post references portions of published test results from various Dell DVS Enterprise reference architectures. We design, build, test and publish E2E enterprise VDI architectures, SKU’d and sold globally. Head over here and have a look for more information.]
There are four core elements that we typically focus on for performance analysis of VDI: CPU, memory, disk, and network. Each plays a uniquely integral role in the system overall with the software in play defining how each element is consumed and to what extent. In this post I’ll go over some of the key considerations when planning an enterprise VDI infrastructure.
Intel’s Ivy Bridge is upon us now, delivering more cores at higher clocks with more cache and supporting faster memory. It is decidedly cheaper to purchase a more expensive pair of CPUs then it is to purchase an entire additional server. For that reason, we recommend running [near] top bin CPUs in your compute hosts as we see measurable benefit in running faster chips. For management hosts you can get by with a lower spec CPU but if you want to get the best return on investment for your compute hosts and get as many users as you can per host, buy the fast CPUs! Our recommendation in DVS enterprise will be following the lateral succession to Ivy Bridge from the Sandy Bridge parts we previously recommended: Xeon E5-2690v2 (IB) vs E5-2690 (SB).
The 2690v2 is a 10 core part using a 22nm process with a 130w TDP clocking in at 3.0GHz and supporting up to 1866MHz DDR3 memory. We tested the top of the line E5-2697v2 (12 cores) as well as the faster 1866MHz memory and saw no meaningful improvement in either case to warrant a core recommendation. It’s all about the delicate balance of the right performance for the right price.
There is no 10c part in the AMD Opteron 6300 line so the closest competitor is the Opteron 6348 (Piledriver). As has always been the case, the AMD parts are a bit cheaper and run more efficiently. AMD clocks lower (with turbo) and due to no hyperthreading feature, executes fewer simultaneous threads. The 6348 also only supports 1600MHz memory but provides a few additional instruction sets. Both run 4 memory channels with an integrated memory controller. AMD also offers a 16c part at its top end in the 6386SE. I have no empirical data on AMD vs Intel for VDI at this time.
Relevant CPU spec comparison, our default selection for DVS Enterprise highlighted in red:

Hyper-V:
The 4 graphs below tell the tale fairly well for 160 concurrent users. Hyper-V does a very good job of optimizing CPU while consuming slightly higher amounts of other resources. Network consumption, while very reasonable and much lower than you might expect for 160 users, is considerably larger than in the vSphere use case in the next example. Once steady state has been reached, CPU peaks right around 85% which is the generally accepted utilization sweet spot making the most of your hardware investment while leaving head room for unforeseen spikes or temporary resource consumption. Memory in use is on the high side given the host had 192GB, but that can be easily remedied by raising to 256GB.





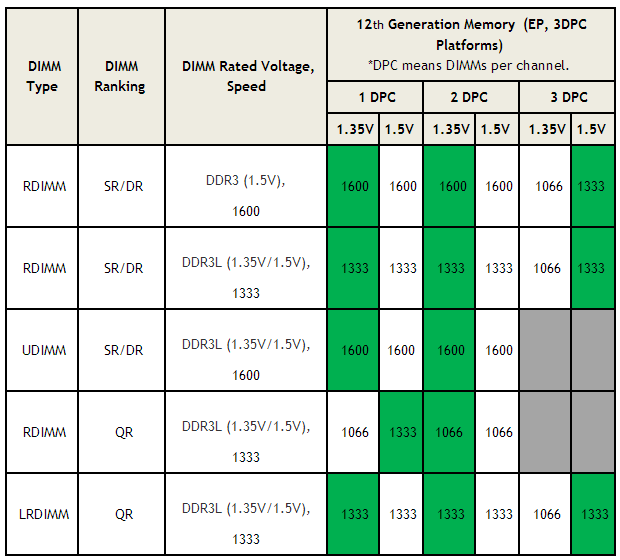
As you can see from the table below, loading all slots on a server via 3 DPC (3 DIMMs per channel) will result in a forced clock reduction to either 1066 or 1333 depending on the DIMM voltage. If you desire to run at 1600MHz or 1866Mhz (Ivy) you cannot populate the 3rd slot per channel which will net 8 empty DIMM slots per server. You’ll notice that the higher memory clocks are also achievable using lower voltage RDIMMs.
Make sure to always use the same DIMM size, clock and slot loading to ensure a balanced configuration. To follow the example of 256GB in a compute host, the proper loading to maintain maximum clock speeds and 4-channel bandwidth is as follows per CPU:

If 256GB is not required, leaving the 4th channel empty is also acceptable in “memory optimized” BIOS mode although it does reduce the overall memory bandwidth by 25%. In our tests with the older sandy bridge E5-2690 CPUs, we did not find that this affected desktop VM performance.
Usable capacity must be sufficient to meet the needs of both Tier1 and Tier2 storage requirements which will differ greatly based on persistent or non-persistent desktops. We generally see an excess of usable capacity as a result of the number of disks required to provide proper performance. This of course is not always the case as bottlenecks can often arise in other areas, such as array controllers. It is less expensive to run RAID10 in fewer arrays to achieve a given performance requirement, than it is to run more arrays at RAID50. Sometimes you need to maximize capacity, sometimes you need to maximize performance. Persistent desktops (full clones) will consume much more disk than their non-persistent counterparts so additional storage capacity can be purchased or a deduplication technology can be leveraged to reduce the amount of actual disk required. If using local disk, in a Local Tier 1 solution model, inline dedupe software can be implemented to reduce the amount of storage required by several fold. Some shared storage arrays have this capability built in. Other solutions, such as Microsoft’s native dedupe capability in Server 2012 R2, make use of file servers to host Hyper-V VMs via SMB3 to reduce the amount of storage required.
Disk performance is another deep well of potential and caveats again related directly to the problems one needs to solve. A VDI desktop can consume anywhere from 3 to over 20 IOPS for steady state operation depending on the use case requirements. Sufficient steady state disk performance can be provided without necessarily solving the problems related to boot or login storms (many desktop VMs being provisioned/ booted or many users logging in all at once). Designing a storage architecture to withstand boot or login storms requires providing a large amount of available IOPS capability which can be via hardware or software based solutions, neither generally inexpensive. Some products combine the ability to provide high IOPS while also providing dedupe capabilities. Generally speaking, it is much more expensive to provide high performance for potential storms than it is to provide sufficient performance for normal steady state operations. When considering SSDs and shared storage, one needs to be careful to consider the capabilities of the array’s controllers which will almost always exhaust before the attached disk will. Just because you have 50K IOPS potential in your disk shelves on the back end, does not mean that the array is capable of providing that level of performance on the front end!
There is not a tremendous performance difference between storage protocols used to access a shared array on the front end, this boils down to preference these days. Fiber Channel has been proven to outperform iSCSI and file protocols (NFS) by a small margin but performance alone is not really reason enough to choose between them. Local disk also works well but concessions may need to be made with regard to HA and VM portability. Speed, reliability, limits/ maximums, infrastructure costs and features are key considerations when deciding on a storage protocol. At the end of the day, any of these methods will work well for an enterprise VDI deployment. What features do you need and how much are you willing to spend?

Keeping tabs on latencies, queue lengths and faults, then reporting each users’ experience into a magic-style quadrant will give you the information required to ascertain if your environment will either perform as designed, or send you scrambling to make adjustments.
There are four core elements that we typically focus on for performance analysis of VDI: CPU, memory, disk, and network. Each plays a uniquely integral role in the system overall with the software in play defining how each element is consumed and to what extent. In this post I’ll go over some of the key considerations when planning an enterprise VDI infrastructure.
CPU
First things first, no matter what you’ve heard or read, the primary VDI bottleneck is CPU. We in CCC/ DVS at Dell prove this again and again, across all hypervisors, all brokers and any hardware configuration. There are special use case caveats to this of course, but generally speaking, your VDI environment will run out of compute CPU before it runs out of anything else! CPU is a finite shared resource unlike memory, disk or network which can all be incrementally increased or adjusted. There are many special purpose vendors and products out there that will tell you the VDI problem is memory or IOPS, those can be issues but you will always come back to CPU.Intel’s Ivy Bridge is upon us now, delivering more cores at higher clocks with more cache and supporting faster memory. It is decidedly cheaper to purchase a more expensive pair of CPUs then it is to purchase an entire additional server. For that reason, we recommend running [near] top bin CPUs in your compute hosts as we see measurable benefit in running faster chips. For management hosts you can get by with a lower spec CPU but if you want to get the best return on investment for your compute hosts and get as many users as you can per host, buy the fast CPUs! Our recommendation in DVS enterprise will be following the lateral succession to Ivy Bridge from the Sandy Bridge parts we previously recommended: Xeon E5-2690v2 (IB) vs E5-2690 (SB).
The 2690v2 is a 10 core part using a 22nm process with a 130w TDP clocking in at 3.0GHz and supporting up to 1866MHz DDR3 memory. We tested the top of the line E5-2697v2 (12 cores) as well as the faster 1866MHz memory and saw no meaningful improvement in either case to warrant a core recommendation. It’s all about the delicate balance of the right performance for the right price.
There is no 10c part in the AMD Opteron 6300 line so the closest competitor is the Opteron 6348 (Piledriver). As has always been the case, the AMD parts are a bit cheaper and run more efficiently. AMD clocks lower (with turbo) and due to no hyperthreading feature, executes fewer simultaneous threads. The 6348 also only supports 1600MHz memory but provides a few additional instruction sets. Both run 4 memory channels with an integrated memory controller. AMD also offers a 16c part at its top end in the 6386SE. I have no empirical data on AMD vs Intel for VDI at this time.
Relevant CPU spec comparison, our default selection for DVS Enterprise highlighted in red:
Performance analysis:
To drive this point home regarding the importance of CPU in VDI, here are 2 sets of test results published in my reference architecture for DVS Enterprise on XenDesktop, one on vSphere, one of Hyper-V, both based on Sandy Bridge (we haven’t published our Ivy Bridge data yet). MCS vs PVS is another discussion entirely but in either case, CPU is always the determining factor of scale. These graphs are based on tests using MCS and R720’s fitted with 2 x E5-2690 CPUs and 192GB RAM running the LoginVSI Light workload.Hyper-V:
The 4 graphs below tell the tale fairly well for 160 concurrent users. Hyper-V does a very good job of optimizing CPU while consuming slightly higher amounts of other resources. Network consumption, while very reasonable and much lower than you might expect for 160 users, is considerably larger than in the vSphere use case in the next example. Once steady state has been reached, CPU peaks right around 85% which is the generally accepted utilization sweet spot making the most of your hardware investment while leaving head room for unforeseen spikes or temporary resource consumption. Memory in use is on the high side given the host had 192GB, but that can be easily remedied by raising to 256GB.
vSphere:
Similar story for vSphere, although the user density below is representative of only 125 desktops of the same user workload. This speaks to another trend we are seeing more and more of which is a stark CPU performance reduction of vSphere compared to Hyper-V for non-View brokers. 35 fewer users overall here but disk performance is also acceptable. In the example below, CPU spikes slightly above 85% at full load with disk performance and network consumption well within reasonable margins. Where vSphere really shines is in it’s memory management capabilities thanks to features the likes of Transparent Page Sharing, as you can see the active memory is quite a bit lower than what has actually been assigned.Are 4 sockets better than 2?
Not necessarily. 4-socket servers, such as the Dell PowerEdge R820, use a different mutli-processor (MP) CPU architecture, currently based on Sandy Bridge EP (E5-4600 family) versus the dual processor (DP) CPU architectures of its dual socket server counterparts. MP CPUs and their 4-socket servers are inherently more expensive, especially considering the additional RAM required to run whatever additional user densities. 2 additional CPUs does not mean twice the user density in a 4-socket platform either! A similarly configured 2-socket server is roughly half the cost of a 4-socket box and it is for this reason that we recommend the Dell PowerEdge R720 for DVS Enterprise. You will get more users on 2 x R720s cheaper than if you ran a single R820.Memory
Memory architecture is an important consideration for any infrastructure planning project. Our experience shows that VDI appears to be less sensitive to memory bandwidth performance than other enterprise applications. Besides overall RAM density per host, DIMM speed and loading configuration are important considerations. In Sandy and Ivy Bridge CPUs, there are 4 memory channels, 3 DIMM slots each, per CPU (12 slots total). Your resulting DIMM clock speed and total available bandwidth will vary depending on how you populate these slots.As you can see from the table below, loading all slots on a server via 3 DPC (3 DIMMs per channel) will result in a forced clock reduction to either 1066 or 1333 depending on the DIMM voltage. If you desire to run at 1600MHz or 1866Mhz (Ivy) you cannot populate the 3rd slot per channel which will net 8 empty DIMM slots per server. You’ll notice that the higher memory clocks are also achievable using lower voltage RDIMMs.
Make sure to always use the same DIMM size, clock and slot loading to ensure a balanced configuration. To follow the example of 256GB in a compute host, the proper loading to maintain maximum clock speeds and 4-channel bandwidth is as follows per CPU:
If 256GB is not required, leaving the 4th channel empty is also acceptable in “memory optimized” BIOS mode although it does reduce the overall memory bandwidth by 25%. In our tests with the older sandy bridge E5-2690 CPUs, we did not find that this affected desktop VM performance.
Disk
There are 3 general considerations for storage that vary depending on the requirements of the implementation: capacity, performance and protocol.Usable capacity must be sufficient to meet the needs of both Tier1 and Tier2 storage requirements which will differ greatly based on persistent or non-persistent desktops. We generally see an excess of usable capacity as a result of the number of disks required to provide proper performance. This of course is not always the case as bottlenecks can often arise in other areas, such as array controllers. It is less expensive to run RAID10 in fewer arrays to achieve a given performance requirement, than it is to run more arrays at RAID50. Sometimes you need to maximize capacity, sometimes you need to maximize performance. Persistent desktops (full clones) will consume much more disk than their non-persistent counterparts so additional storage capacity can be purchased or a deduplication technology can be leveraged to reduce the amount of actual disk required. If using local disk, in a Local Tier 1 solution model, inline dedupe software can be implemented to reduce the amount of storage required by several fold. Some shared storage arrays have this capability built in. Other solutions, such as Microsoft’s native dedupe capability in Server 2012 R2, make use of file servers to host Hyper-V VMs via SMB3 to reduce the amount of storage required.
Disk performance is another deep well of potential and caveats again related directly to the problems one needs to solve. A VDI desktop can consume anywhere from 3 to over 20 IOPS for steady state operation depending on the use case requirements. Sufficient steady state disk performance can be provided without necessarily solving the problems related to boot or login storms (many desktop VMs being provisioned/ booted or many users logging in all at once). Designing a storage architecture to withstand boot or login storms requires providing a large amount of available IOPS capability which can be via hardware or software based solutions, neither generally inexpensive. Some products combine the ability to provide high IOPS while also providing dedupe capabilities. Generally speaking, it is much more expensive to provide high performance for potential storms than it is to provide sufficient performance for normal steady state operations. When considering SSDs and shared storage, one needs to be careful to consider the capabilities of the array’s controllers which will almost always exhaust before the attached disk will. Just because you have 50K IOPS potential in your disk shelves on the back end, does not mean that the array is capable of providing that level of performance on the front end!
There is not a tremendous performance difference between storage protocols used to access a shared array on the front end, this boils down to preference these days. Fiber Channel has been proven to outperform iSCSI and file protocols (NFS) by a small margin but performance alone is not really reason enough to choose between them. Local disk also works well but concessions may need to be made with regard to HA and VM portability. Speed, reliability, limits/ maximums, infrastructure costs and features are key considerations when deciding on a storage protocol. At the end of the day, any of these methods will work well for an enterprise VDI deployment. What features do you need and how much are you willing to spend?
Network
Network utilization is consistently (and maybe surprisingly) low, often in the Kbps/ per user. VDI architectures in and of themselves simply don’t drive a ton of steady network utilization. VDI is bursty and will exhibit higher levels of consumption during large aggregate activities such as provisioning or logins. Technologies like Citrix Provisioning Server will inherently drive greater consumption by nature. What will drive the most variance here is much more reliant on upstream applications in use by the enterprise and their associated architectures. This is about as subjective as it gets, so impossible to speculate in any kind of fashion across the board. Now you will have a potentially high number of users on a large number of hosts, so comfortable network oversubscription planning should be done to ensure proper bandwidth in and out of the compute host or blade chassis. Utilizing enterprise-class switching components that are capable of operating at line rates for all ports is advisable. Will you really need hundreds of gigs of bandwidth? I really doubt it. Proper HA is generally desirable along with adherence to sensible network architectures (core/ distribution, leaf/spline). I prefer to do all of my routing at the core leaving anything Layer2 at the Top of Rack. Uplink to your core or distribution layers using 10Gb links which can be copper (TwinAx) for shorter runs or fiber for longer runs.In Closing
That about sums it up for the core 4 performance elements. To put a bow on this, hardware utilization analysis is fine and definitely worth doing, but user experience is ultimately what’s important here. All components must sing together in harmony to provide the proper level of scale and user experience. A combination of subjective and automated monitoring tests during a POC will give a good indication of what users will experience. At Dell, we use Stratusphere UX by Liquidware Labs to measure user experience in combination with Login Consultants LoginVSI for load generation. A personal, subjective test (actually log in to a session) is always a good idea when putting your environment under load, but a tool like Stratusphere UX can identify potential pitfalls that might otherwise go unnoticed.Keeping tabs on latencies, queue lengths and faults, then reporting each users’ experience into a magic-style quadrant will give you the information required to ascertain if your environment will either perform as designed, or send you scrambling to make adjustments.











No comments: